nkfを通すと、どういうわけか全角のマイナス(ハイフン?)が文字化けする。文字コード変換をしなくても化ける。
実験用に用意したのは「-」だけが入ったファイル。UTF-8の環境で作ったもの。
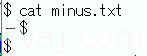
16進ダンプ。
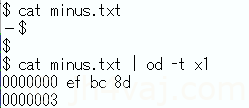
これをnkfを通す。出力文字コードはUTF-8。つまり、コード変換はなし。

なんで?
iconvならこんなことは起きない。
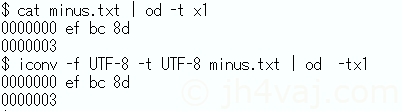
化けていない。
最初にこれに気づいたのは、CP932なファイルをnkfで変換したとき。「-」が化けるので、CP932からUTF-8への変換で何か問題があるのかなと。でも、追っかけてみたらUTF-8からUTF-8への変換(=無変換)でも起きることがわかった。ここは、iconvを使うことにするか。

これはまた別の問題。
【追記】
MS-UnicodeとIBM-Unicodeの違いであると教えてもらった。
そんな物があるとはつゆ知らず…。検索したら、このページが見つかった。

ということで、改めてnkfのmanを見るとこういうオプションがあった。
--no-best-fit-chars
Unicode からの変換の際に、往復安全性が確保されない文字の変換を行いません。
Unicode からUnicode の変換の際に -x と共に指定すると、nkf を UTF 形式の
変換に用いることができます。 (逆に言えば、これを指定しないと一部の文字が
保存されません)
パスに関わる文字列を変換する際には、このオプションを指定することを強く推奨
します。
なるほど。この –no-best-fit-chars オプションを使えばいいのか。
コメント